[sc name=quote-embed-post]2024/04/14/momento-vera-lista-di-liste/[/sc]
Dovevo finire di scriverlo ieri questo, ma, puntualmente, finito un progettino bisogna subito iniziarne un altro (no spoiler), e non c'è tempo per il #blogging. La pagina rilasciata ieri, nonostante comunque non mi abbia rubato così tanto tempo perché è pur sempre una paginetta, mi ha presa un po' alla sprovvista considerando che l'avevo iniziata addirittura questo lunedì. (6 giorni son passati...) 😳
Il motivo è buffo e per nulla legato alla difficoltà di #programmazione in sé (ho fatto cose peggiori), ma al fatto che puntualmente le altre cose non funzionano mai come dovrebbero, e quindi bisogna fare delle #hack, e poi dopo altro test si vede che da quelle hack si scassano altre cose, e via quindi di altre hack per sistemare i #problemi... E allora io ad una certa mi seccavo, e dunque "aight then, see you tomorrow ☠️"
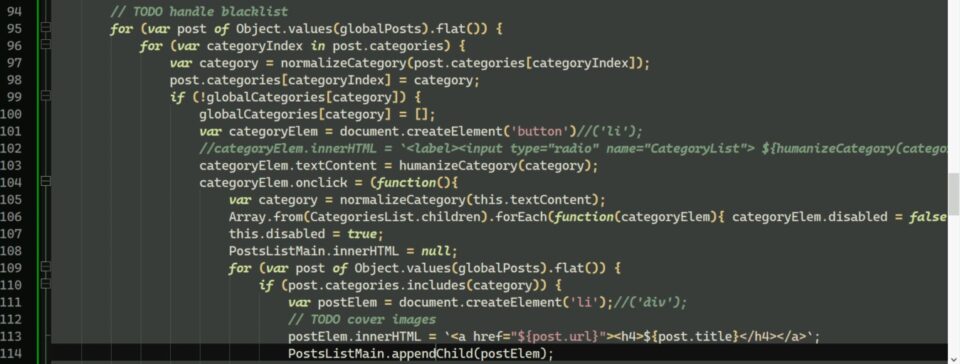
- Per il sitoctt è stato relativamente semplice: mi appoggio alla pagina di ricerca statica del sito, parsando tutto l'HTML, che per quanto rotta (e per questo evito di far sapere che esiste) racchiude il contenuto di tutte le pagine compilate del sito. Quindi, raccolgo tutti i link ai post da tutte le pagine di categoria. 😺
- Quei link però sono solo-testo, quindi per prendere l'immagine di copertina ho dovuto aggiornare staticoso dopo mesi solo per fargli scrivere gli URL in attributi
datadell'HTML. Poi però mettiamoci pure che a volte questi vengono scritti rotti perché la sostituzione delle variabili non funziona in quel punto del #codice (e io non lo sistemerò mai), e anche che quando manca una copertina allora devo per forza prenderla dal contenuto della pagina, ho dovuto comunque complicare di più il #JavaScript... 😡
- Quei link però sono solo-testo, quindi per prendere l'immagine di copertina ho dovuto aggiornare staticoso dopo mesi solo per fargli scrivere gli URL in attributi
- Per il fritto misto, bel #casino, innanzitutto perché per stabilità e sicurezza volevo evitare di usare i proxy CORS, e poi per efficienza e velocità volevo minimizzare il più possibile le richieste di rete necessarie (paginazione è cacca)... quindi anche qui mi appoggio alla ricerca (in JSON) del mirror statico del sito, anziché direttamente a WordPress; nel file ci sono tutti i post con i metadati necessari. 😸
- Ganzo, se non fosse che ho sprecato chissà quanto tempo solo per le immagini; e totalmente invano, perché poi alla fine ho dovuto rassegnarmi a includere nel JSON tutti i dump #HTML dei post (ciò che volevo evitare, perché fatto così si appesantirà molto velocemente, ops) ed estrarre la prima immagine ricorrente in quelli. Non capisco se il problema ha a che fare con #Jekyll, la sua versione fornita da GitHub Pages, o ancora il parser Liquid di Ruby, perché con un altro parser (LiquidJS) ho verificato che il mio codice per estrarre gli URL dal markup è corretto... solo che poi messo lì non funge. Provato anche il plugin "jekyll-firstimage" trovato a casissimo, ma ovviamente non è servito, dava addirittura errore ad installarsi nel processo di build. 👹