
Stasera ho in mano l'ennesimo caso di "skill issue a posteriori", cioè di una roba che viene da chiedermi come ho fatto a non pensarci prima... vabbè va. Convertire siti #WordPress in file pseudo-Markdown per i generatori statici non è mai stato semplice quanto 30 righe scarsissime di #XSLT. 🔥
A differenza di anche solo 2 anni fa, in realtà, negli ultimi mesi sono usciti su GitHub ancora nuovi programmini e script, per convertire file di esportazione #XRSS di WordPress in file Markdown — giusto per reference, li ho raccolti su https://memos.octt.eu.org/m/X6v7w4FccbBon6J6jxCYoJ — però, oggi che ne cercavo uno ideale, comunque ho visto che fanno tutti cahà. ☠️
Gli autori di questi programmi pensano di essere culi intelligenti, e quindi non solo leggono l'XML di esportazione per convertire i metadati in YAML e salvare su multipli file con il nome giusto...... ma convertono tutto il corpo #HTML in #Markdown, cosa che non so come altro descrivere se non come la mossa più stupida dell'universo, perché è una procedura lossy che letteralmente rompe il contenuto, se non vengono considerati tutti i casi limite. 😵
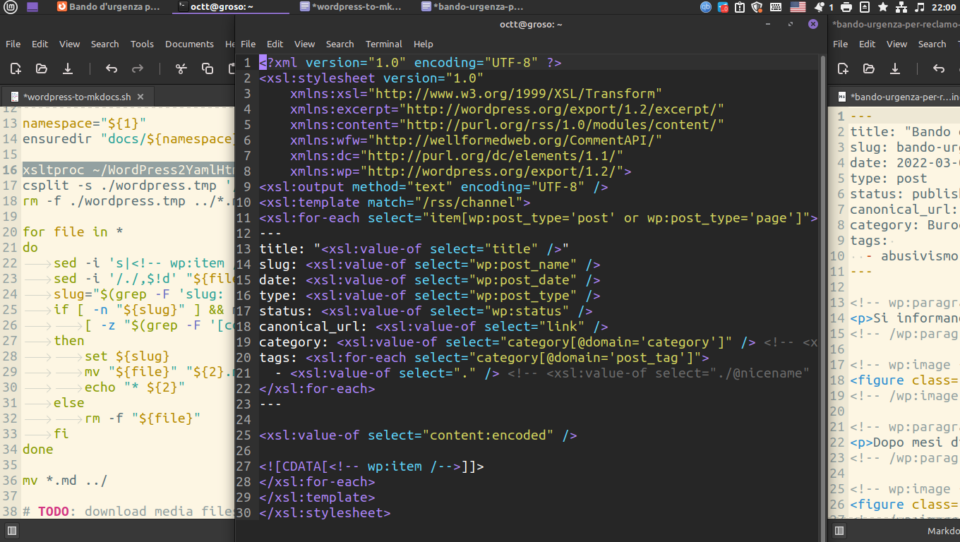
Tutta questa scienza però evidentemente non serve, se un foglio di trasformazione XML tirato su in 10 minuti è sufficiente... yikes. L'ho caricato per i consumatori (inclusa me di qualche ora dopo) sulla mia repo di monnezza: https://gitlab.com/octospacc/Snippets/-/blob/main/WordPress-To-Yaml+Html.xslt. Per usarlo, basta darlo come primo argomento al programma xsltproc (che è nelle repo di Debian, quindi presumo ovunque), e come secondo argomento specificare il file .xml esportato da WordPress... 🥰
Chiaramente, troppa #magia con così poco codice non è possibile, quindi questo metodo da in output un enorme flusso di testo con tutte le pagine "esportate" concatenate... e si dovrà usare uno #script aggiuntivo per separare il file singolo in tanti dal nome giusto; appena una manciata di righe in qualsiasi linguaggio, ma questo è come lo faccio io in sh (per l'archivioctt): https://gitlab.com/octospacc/archivioctt/-/blob/mkdocs/scripts/wordpress-to-mkdocs.sh 😽
(Per chi non sa leggere: viene usato "<!-- wp:item /-->" come separadore, quindi quello deve essere usato per splittare. Opzionalmente si possono aggiungere e modificare i filtri XPath usati nel xsl:for-each per includere ed escludere tipi di robe, ad esempio includere solo i post, o solo le pagine pubbliche, nonché aggiungere e togliere proprietà ai metadati YAML... però di base è già alla massima goduria!!!)