
Ieri, cercando della roba riguardo #TiddlyWiki (che non ho trovato e ho dovuto fare io quindi, comunque), ho per sbaglio trovato quest'altra cosina... (con questo #software è praticamente sempre così, onestamente, le cose più ganze si trovano sempre per caso, la #community è #pazza). 😏
..."Search your nodejs wiki in Google", "TiddlyWiki5: Combine TW5 and search engine results"... nella pratica, è un #userscript che aggiunge sulla pagina di ricerca di diversi motori #web dei link che riportano a quei tiddler che combaciano con la ricerca. Il senso è che, se hai (come me) diversi link in #wiki (salvati dopo che in passato si sono rivelati almeno una volta utili), questo #strumento evita di farti finire troppo spesso nella #situazione in cui impazzisci a trovare una #pagina #online per una determinata cosa che non ricordavi di avere già salvato. Non ci avevo mai pensato, ma questo #strumentopolo è effettivamente #utile, infatti l'ho installato ora. 💯
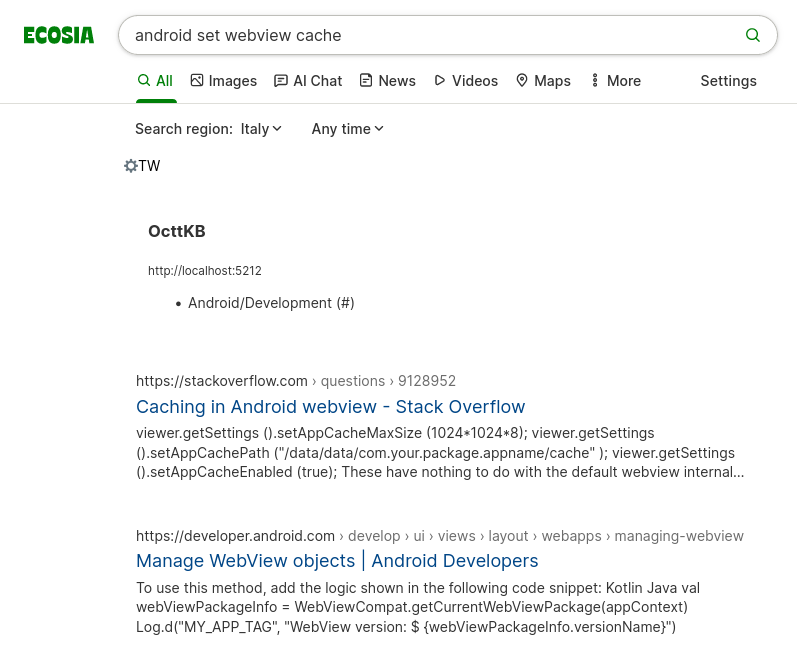
L'ho impostato su #Ecosia (che alla fine è banalmente DuckDuckGo con qualcosa in meno e qualcosa in più), per un semplice motivo:
- Su #Google pare funzionare correttamente, ma io #GoogleSearch non lo preferisco. 🤮
- Su #DuckDuckGo è #rotto, e provando a sistemare il #codice in pochi minuti non ho risolto il problema. 😔
- Su Ecosia non ha funzionato da subito, ma disattivando #JS sul suo dominio e sistemando una piccola parte dello #script, subito ha iniziato a fungere. La versione no-JS di Ecococosia è sorprendentemente ben fatta, quindi ad usare quella non si perde granché. 😺
- Il resto sono #motori minori (di cui nessuno è un meta-motore, tra l'altro), a parte #Bing... che non c'è motivo di usare, in quanto è banalmente DDG/Ecosia ma con la certezza di datamining, poco simpatico. 🦧
#Ahimé, dopo aver risolto questo primo #intoppo, altro #problema, che esiste praticamente solo perché questi 2 fattori sono allo stesso tempo veri:
- L'userscript ha bisogno di un server TiddlyWiki NodeJS per fare le sue richieste (non può leggere l'HTML della versione statica classica, deve usare le #API) ma, a quanto pare, permettere qualsiasi filter query (cosa praticamente necessaria per questo uso) su un #server aperto su Internet ti espone ad attacchi DoS (e posso immaginare come mai, conoscendo come funziona il Tiddlino)... quindi, andrebbe tenuto tutto in LAN. 🚧
- Da non si sa quando, #Firefox (e, mi è parso di capire, anche gli altri browser) bloccano la navigazione da una pagina residente in Internet verso posizioni locali (
file://,127.xxx.xxx.xxx,192.168.xxx.xxx), sia con metodi #JavaScript (comprensibile, lato sicurezza)... che con metodi manuali come il semplice click su un #link<a>(il che è assolutamente incomprensibile, invece). Ho cercato e cercato, e ho trovato (non senza confusione), qualche #soluzione, che però (e te pareva) non ne vuole sapere di #funzionare... o risolvo questo problema, o devo ogni volta aprire il collegamento in una nuova scheda facendo un passaggio extra (o copia e incolla, o Ctrl+click e poi refresh), che è una merda. 🤧
#Mannaggia!!! Vedi tu se non escono sempre problemi perché qualcuno decide che non c'è abbastanza #sicurezza, e partendo con buone intenzioni va puntualmente oltre. La cosa peggiore di tutte, inoltre, è che la cancellazione della #navigazione avviene in maniera #criptica, senza alcun avviso, errore, o spiegazione: semplicemente non accade nulla. Ma, lasciando da parte per un attimo le mie opinioni su chi dovrebbe essere licenziato in tronco, nel quel dove in cui si sviluppano i #browser, vediamo come ho perso il mio #tempo dopo: 🌚
- Ho provato a bypassare questa #schifezza del #navigatore creando dei domini personali in
/etc/hosts, che puntassero al PC come #localhost o in #LAN... e non ha funzionato; evidentemente, il blocco della navigazione avviene in base alla risoluzione dell'indirizzo, non necessariamente in base alla parte letterale dell'URL (cosa che spiegherebbe come mai all'inizio la pagina pare caricare, ma è dopo giusto qualche istante che si ferma). 🚨 - Mi è venuto in mente di tenere un #webserver locale che semplicemente fa da proxy per il motore di ricerca, permettendomi di accedervi nel browser dallo stesso indirizzo del server wiki... e ho provato a settare il mio nginx, nello stesso identico modo in cui ho sempre fatto per tanti altri #siti, ma per Ecosia non ne voleva proprio sapere di andare. 🛑
...e ho così finito le #idee per qualche minuto. Turns out però, e mi chiedo come ho fatto a non pensarci prima, che il #metodo meno tendente a #rogne sarebbe stato #modificare lo script per visualizzare i link alla versione online della mia #KnowledgeBase, anche se i dati li continua a ricavare dal server locale. ...E, infatti, ci ho messo 3 minuti e ho risolto il mio casino. Vorrei tanto avere una mini-me virtuale, magari come widget sul desktop, che mi suggerisce i modi giusti di fare le cose quando nota che io reale sto #cringiando. 😫
Ora, a parte mettere questo sistema in funzione anche sul telefono (cosa immediata) ci sarebbero almeno 3 cose da fare:
- Necessaria: mettere sul mio homeserver (dove tengo il robo con le API) un servizio che scarica di continuo aggiornamenti della #OcttKB da #Git, e riavvia il server Node quando necessario. Nulla di difficile, ma è palloso. ⚽
- Preferibile: mandare una pull request per lo userscript con le #modifiche che ho fatto, incluse quelle di compatibilità, o almeno caricare su qualche mio robo pubblico la mia versione. Nulla di complesso, ma è scocciante. 🧻
- Idealissima: Portare al livello estremo la #UX di questa estensione, integrando sicuramente dei risultati di #ricerca che facciano quantomeno vedere il contenuto che ha causato il match, e magari addirittura che supportino un formato custom definito in-wiki per la #visualizzazione di diversi tipi di #dati in modo specifico per ogni situazione (ad esempio, una differenza tra corrispondenze in #pagine di #note, pagine che sono solo ammassi di link, e così via...). E questo è proprio la #lamegafine, invece, non ci sono mezzi termini. Però quanto sarebbe top. ☠️