
[sc name="quote-embed-post"]2023/12/13/493[/sc]
Viviamo tutti nello stesso mondo fatto di (Uni)codice, ma gli unici a soffrire a riguardo siamo sempre e soltanto noi #programmatori... 💀️
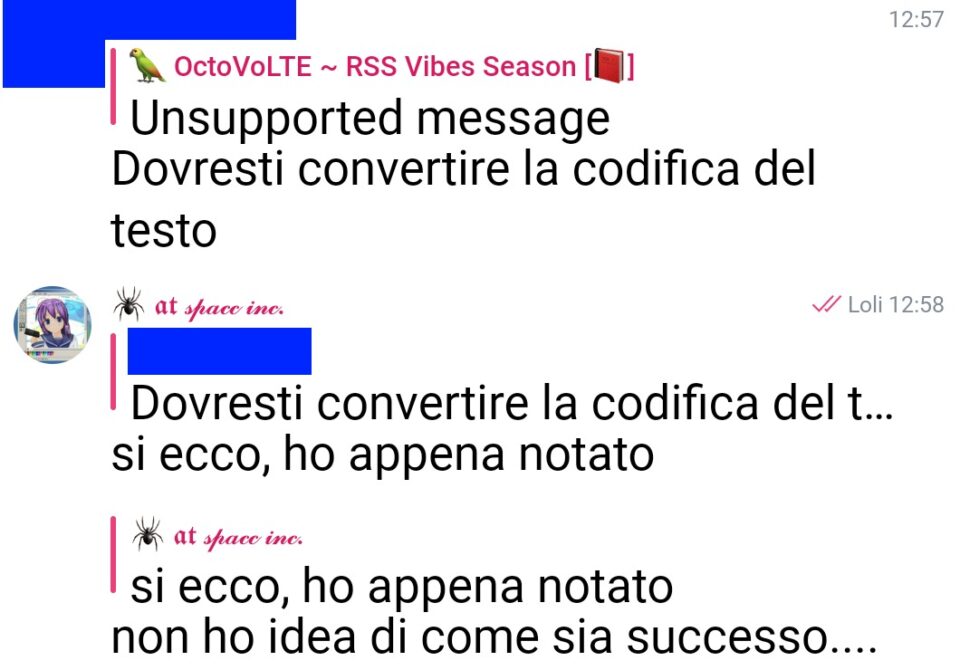
Alla fine è bastato poco per risolvere. Ma a sto giro è stata questione di culo. (Spiegazione tecnica: <🤓️> Il documento RSS iniziale e quello finale hanno complessivamente la codifica correttamente specificata, il problema è che per modificare il contenuto #HTML dei post di ogni elemento del feed, essendo questo salvato come testo semplice (CDATA) e non come XML, esso va parsato come documento a sé... ma non essendo un documento HTML completo, non contiene da nessuna parte una specifica della codifica quando estratto dal contesto XML, e quindi automaticamente lo status di #UTF8 va in mona; È bastato usare la funzione integrata di PHP mb_convert_encoding($testohtml, 'HTML-ENTITIES', 'UTF-8'); per sistemare l'HTML prima del #parsing, per risolvere la rogna. </🤓️>)